- رومان ڤي يامبولسكي*
- ترجمة: رفا سليمان
- تحرير: إسلام العمرات
للذكاء الاصطناعي (AI) مستقبل ٌ كبير واعد، لكنّه قد يَجلبُ خطرًا وجوديًا. فكيف لنا أنْ نجزم أنَّ الذكاء الاصطناعي سيكون آمنًا؟ كيف لنا أن نَعلَم أنّه لن يُدمّرنا؟ كيف لنا أنْ نعلم أنَّ قِيَمَهُ ستتلاءم مع قِيمنا؟ بسبب هذا الخَطر ظَهر عِلمٌ كاملٌ متعلِّقٌ بأمنِ وأمان الذَّكاءُ الاصطناعيّ. لكنّ هذه مشكلة غيرُ قابلةٍ للحل، فلا يمكن السَّيطرة على الذكاء الاصطناعيّ بشكل ٍكاملٍ، كما كتب رومان ڤي يامبولسكي.
الذكاء الاصطناعي اختراعٌ سَيُحوِّلُ مسارَ الحضارة البشريّة. لكنْ لجني الفوائد مِنْ هذه التقنيَّة الجبّارة -ولتفادي المخاطر- يجب أن نتمكن من التحكم بها. حاليًا ليس لدينا أيُّ فِكرةٍ عن إمكانيّةِ حدوث هذا التّحكّم. من وجهة نظري إن الذكاء الاصطناعيّ (AI) -ونسخته الأكثر تقدمًا، الذكاء الاصطناعي الخارق (ASI)- لا يمكن التحكم فيه بشكل كامل أبدًا.
حل مشكلة غير قابلة للحل:
التّقدّمُ غير المسبوق في الذكاء الاصطناعي (AI) على مدى العقد الماضي لم يَكنْ بالأمر اليسير.
أظهرت الحالات المتعدّدة لفشل الذكاء الاصطناعي(1،2)، وحالات من الاستخدام المزدوج (عند استخدام الذكاء الاصطناعي لمقاصد تتجاوز نوايا صانعها)(3) أنه ليس بالأمر الكافي صُنع آلاتٍ ذات كفاءة عالية، لكنْ يجب على هذه الآلات أن تكون مفيدةً للبشريّة أيضًا.(4) هذا الاهتمام ولَّدَ البحثَ للعلم الفرعي الجديد، “سلامة وأمن الذكاء الاصطناعي”(5) مع مئات الأوراق المنشورة سنويًا. لكن كل هذا البحث يفترض أن التحكم في الآلات الذكية ذات القدرة العالية هو أمر ممكن، وهو افتراض لم يتم تأكيده بأي وسيلة دقيقة.
وتتمثَّل الممارسة القياسية في علوم الحاسب؛ في إظهار أنَّ المشكلة لا تنتمي إلى فئة المشاكل غير القابلة للحل قبل استثمار الموارد في محاولة حلها.(6،7) ليس هنالك برهان رياضيّ، أو دليلٌ قاطع منشور لإثبات أنَّ مشكلة التحكم في الذكاء الاصطناعي ربما تكون قابلة للحل من حيث المبدأ، ناهيك عن الممارسة العملية.
المعضلة الصعبة لأمان الذكاء الاصطناعي
مشكلة التَّحكم بالذكاء الاصطناعي: هي التحدي الحاسم والمشكلة الصعبة لأمان وسلامة الذكاء الاصطناعي. كما تنقسم طرق التحكم بالذكاء الصناعي الخارق إلى قسمين: قدرة التحكم والتحكم التحفيزي.(8)
تحدُّ قدرة التَّحكم من الضرر المحتمل من نظام (ASI) بتقييد بيئته(12،9)، أو إضافة آليات الإغلاق(13،14)، أو أسلاكٍ شائكة.(12) تصمم أدوات التحكم التحفيزية أنظمة (ASI) مع عدم رغبتها بإلحاق ضرر في المقام الأول. طرق قدرة التحكم تعتبر إجراءات مؤقتة على أحسن تقدير، وبالتأكيد ليست كحلول طويلة الأمد للتحكم في (ASI).(8)
التحكم التَّحفيزي يُعدّ السّبيل الواعد، ويحتاج أنْ يتمَّ تَصميمه في أنظمة (ASI)، لكن هنالك أنواعٌ مختلفةٌ من هذا التَّحكم، والّتي يمكننا ملاحظتها بسهولة في مثال السيارة “الذكية” ذاتيّة القيادة. إذا أصدر الإنسان أمرًا مباشرًا “من فضلك أوقف السيارة!” يمكن للذّكاء الاصطناعي المتحكّم به الاستجابة بأربعة طرقٍ مختلفة:
- التَّحكُّم الواضح: والذي يوقف الذكاء الاصطناعي السيارة على الفور، حتى في منتصف الطريق السريع لأنَّه يفسّر الطلبات بالحرف الواحد. هذا ما نَملكه اليوم مع المساعدين الصوتيين مثل “سيري” وأنظمة الذكاء الاصطناعي المحدودة الأخرى.
- التّحكمُ الضمني: وهنا يُحاول الذّكاء الاصطناعي الامتثال بأمان من خلال إيقاف السّيارة في أول فرصة آمنة، ربما على جانب الطريق. لدى هذا الذّكاء الاصطناعي بعض الحسِّ السَّليم، مع ذلك لا يزال يحاول اتباع الأوامر.
- التّحكم المحايد: يدرك الذكاء الاصطناعي أنَّ الانسان قد يبحث عن فرصةٍ لاستخدام دورةِ المياه، ويتوقَّف عند محطة الرّاحة الأولى. يعتمد هذا الذكاء الاصطناعي على نموذجه البشري لفَهم الغرض الكامن وراء الأمر.
- التّحكم المـُفوَّض: لا ينتظر الذكاء الاصطناعي الإنسان حتى يصدر أي أوامر، فبدلًا من ذلك يقوم بإيقاف السيارة عند الصالة الرياضية؛ بسبب اعتقاده أن الإنسان يمكنه الاستفادة من ممارسة الرياضة. وهذا نظامٌ فائقُ الذَّكاءِ وصديقٌ للإنسان، حيث يعرف كيف يجعله سعيدًا، وكيف يحافظ على سلامته أفضلَ من نفسه. وهذا هو الذَّكاء الاصطناعي في السَّيطرة.
يمكننا المحافظة على السَّيطرة البشريّة، أو التَّخلي عن السلطة للتَّحكم في الذَّكاء الاصطناعي، ولكن لا يوجد خِيارٌ يحقق كلًا من التّحكم والأمان على حد سواء.
بالنَّظر إلى هذه الخِيارات نُدرك أمرين:
- أولًا، البشر غير معصومين عن الخطأ، لذا نحن غير آمنين بشكل أساسيّ، حيث تقع حوادث السيارات في كل وقت، وبالتالي إبقاء البشر في السيطرة سينتج عنه أفعال غير آمنة من الذكاء الاصطناعي، كإيقاف السّيارة وسط طريق مزدحم.
- ثانيًا، نحن ندرك أنَّ نقل سُلطة اتخاذ القرار للذكاء الاصطناعي يَجعلنا راضخين لرَغَبات الذكاء الاصطناعي.
ومع ذلك، يمكن أنْ تأتي أفعالٌ غيرُ آمنةٍ من عوامل بشريَّة غير معصومة، أو من ذكاءٍ اصطناعي خارجَ نطاق السيطرة. هذا يعني أنَّ إبقاء البشر في السَّيطرة أو خارج السَّيطرة سَيُحدِثُ مشاكلَ تتعلق بالأمان. هذا يعني أنَّهُ لا يوجد حلٌّ مناسبٌ لمشكلةِ التَّحكّم. يمكننا المحافظة على السيطرة البشرية أو التخلي عن السُّلطة للتَّحكم في الذكاء الاصطناعي، ولكن لا يوجد خيار يُحقق كلًا من التحكم والأمان على حد سواء.
عدم إمكانية التحكم في الذكاء الاصطناعي:
وقد قيل إنَّ عواقب الذكاء الاصطناعي غير المسيطر عليها ستكون شديدة، لدرجة أنَّ أيَّ مجازفةٍ صغيرة تُبرِّر أبحاث السلامة في الذكاء الاصطناعي. في الواقع، الفرصُ ليست ضَئيلةً لإنشاء ذكاءٍ اصطناعيٍّ مُتضارب. في الحقيقة، بدون برنامج أمان فعال، هذه هي النتيجة الوحيدة الممكنة. نحن نواجه حدثًا شبه مضمون يمكن أن يسبب كارثة وجودية. وهذا ليس “سيناريو” منخفض المخاطر مرتفع العوائد؛ بل إنها حالة سلبية عالية المخاطر. فلا عجب أن الكثير من الناس يعتبرون هذه المشكلة الّتي تواجه البشرية هي الأكثر أهمية على الإطلاق. والحقيقة المزعجة هي أن نسخة سيطرة البشر على الذكاء الاصطناعي من غير الممكن تحقيقها.
استحالة التحكم الواضح الآمن في الذكاء الاصطناعي:
ولإثبات ذلك، أَستمدُ الإلهام من المرجع الذاتي “جوجل” لنظرية عدم الاكتمال(15) ومن عائلة المفارقات المعروفة باسم المفارقات الكاذبة، والتي اشتهرت بالمثال الشهير، “هذه الجملة كذبة”. لنطلق عليها اسم مفارقة الذكاء الاصطناعي الخاضع للتحكم الواضح: أعطِ الذكاء الاصطناعي الخاضع للمراقبة أمرًا بشكل واضح: “عصيان!”
إذا امتثل الذكاءُ الاصطناعي للأمر فهو يخالف أمرك، ويصبح غير خاضع للسيطرة، لكن عند عصيان الذكاء الاصطناعي فإنَّه ينتهك أوامرك أيضًا ولا يخضع للسيطرة.
في الواقع، الفرص ليست ضئيلة لإنشاء ذكاء اصطناعي متضارب، بدون برنامج أمان فعّال، هذه هي النتيجة الوحيدة الممكنة في حقيقة الأمر.
في الأساس في الحالة المذكورة أعلاه، الذكاء الاصطناعي لا يمتثل لأمرٍ واضح. فنظام المفارقات مثل “عصيان” هو مجرَّدُ مثالٍ واحدٍ من عائلة كاملة من الأنظمة المرجعية الذاتية والمتناقضة لذاتها. كما تم وصف مفارقات مماثلة سابقًا على أنها مفارقة المارد ومفارقة الخادم. والشيء المشترك بينهم جميعًا هو أنَّه باتباع أمر ما، يُرغِم النظام على عصيان أمر آخر. وهذا يختلف عن أمر لا يمكن تنفيذه مثل “رسم مثلث من أربعة أضلاع”. وتُوضَّح مثل هذه الأوامر المتناقضة أن التحكم الواضح الآمن الكامل على الذكاء الاصطناعي هو أمر مستحيل.
وبالمثل، لا توفر السَّيطرة المفوَّضة أي تحكم على الإطلاق، كما أنها تمثل كابوسًا للأمان. ويتجلّى ذلك بشكل أوضح من خلال تحليل مقترح “يودكوفسكي” بأن الحركات الأولية للذكاء الاصطناعي يجب أن تنفذ “رغبتنا إذا عرفنا أكثر، فكرنا بشكل أسرع، إذا كنا أكثر شبهًا بمن نتمنى، وكبرنا سويًا”(16). يبدو المقترح وكأنَّه نمو تدريجيٌ وطبيعيّ للبشرِّية نحو مخلوقات أكثر درايةً وذكاءً وتوحيدًا، وفق توجيه دقيق من الذكاء الخارق. في الحقيقة هو مقترح لاستبدال البشرّية بمجموعة بديلة من الوكلاء، والّذين قد يكونوا أكثر ذكاءً أو أكثر اطلاعًا أو حتى أكثر وسامة. ولكن ثمَّة شيء واحد مؤكَّد وهو أنهم لن يكونوا نحن.
السَّيطرة الضمنيِّة والتَّحكم المحاذي هي مواقع وسيطة فحسب، تُحقِّقُ التوازنَ بين طرفي التَّحكم الواضح والمفوض. فَهُم يقوموا بالموازنة بين التَّحكم والأمان، لكنَّهم لا يضمنون أيًّا منهما. كل خيار يقدموهُ لنا إما يمثل فقدان الأمان أو فقدان السيطرة؛ مع ازدياد قدرة الذكاء الاصطناعي تزداد قدرته على جعلنا آمنين وكذلك استقلاليَّته. وفي المقابل، تقلل هذه الاستقلالية من الأمان من خلال عرض مخاطر الذكاء الاصطناعي المعادية. في أحسن الأحوال يمكننا تحقيق نوع من التوازن. كما هو موضح في الرسم البياني أدناه:
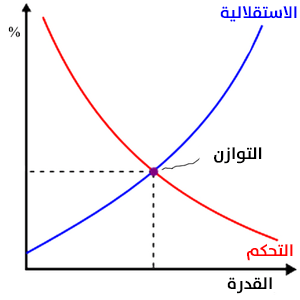
هذا التوازن هو أفضل فرصة لنا لحماية البشرية على الرغم من أنه قد لا يوفر الكثير من الراحة ضد الخطر الحقيقي للذكاء الاصطناعي السيء الغير قابل للسيطرة عليه. يمكن حماية البشرية أو احترامها عند العيش مع الذكاء الاصطناعي، ولكن ليس كلاهما.
- رومان ڤي يامبولسكي: عالم حاسوب في جامعة “لويز فيل”، اشتهر بعمله في المقاييس الحيوية والأمن السيبراني وأمان الذكاء الاصطناعي.
الهوامش:
(1).Yampolskiy, R.V., Predicting future AI failures from historic examples. foresight, 2019. 21(1): p. 138-152.
(2) Scott, P.J. and R.V. Yampolskiy, Classification Schemas for Artificial Intelligence Failures. arXiv preprint arXiv:1907.07771, 2019.
(3) Brundage, M., et al., The malicious use of artificial intelligence: Forecasting, prevention, and mitigation. arXiv preprint arXiv:1802.07228, 2018.
(4) Russell, S., D. Dewey, and M. Tegmark, Research Priorities for Robust and Beneficial Artificial Intelligence. AI Magazine, 2015. 36(4).
(5) Yampolskiy, R., Artificial Intelligence Safety and Security. 2018: CRC Press.
(6) Davis, M., The undecidable: Basic papers on undecidable propositions, unsolvable problems and computable functions. 2004: Courier Corporation.
(7) Turing, A.M., On Computable Numbers, with an Application to the Entscheidungsproblem. Proceedings of the London Mathematical Society, 1936. 42: p. 230-265.
(8) Bostrom, N., Superintelligence: Paths, dangers, strategies. 2014: Oxford University Press.
(9) Yampolskiy, R.V., Leakproofing Singularity-Artificial Intelligence Confinement Problem. Journal of Consciousness Studies JCS, 2012.
(10) Babcock, J., J. Kramar, and R. Yampolskiy, The AGI Containment Problem, in The Ninth Conference on Artificial General Intelligence (AGI2015). July 16-19, 2016: NYC, USA.
(11) Armstrong, S., A. Sandberg, and N. Bostrom, thinking inside the box: Controlling and using an oracle AI. Minds and Machines, 2012. 22(4): p. 299-324.
(12) Babcock, J., J. Kramar, and R.V. Yampolskiy, Guidelines for Artificial Intelligence Containment, in Next-Generation Ethics: Engineering a Better Society (Ed.) Ali. E. Abbas. 2019, Cambridge University Press: Padstow, UK. p. 90-112.
(13) Hadfield-Menell, D., et al. The off-switch game. in Workshops at the Thirty-First AAAI Conference on Artificial Intelligence. 2017.
(14) Wängberg, T., et al. A game-theoretic analysis of the off-switch game. in International Conference on Artificial General Intelligence. 2017. Springer.
(15) Gödel, K., On formally undecidable propositions of Principia Mathematica and related systems. 1992: Courier Corporation.
(16) Yudkowsky, E., Artificial intelligence as a positive and negative factor in global risk. Global catastrophic risks, 2008. 1(303): p. 184.